 "
"
Team:Paris Bettencourt/Semantic containment
From 2012.igem.org

- Main
- Team
- Project
- Achievements
- Human Practice
- Safety
- Notebook
- Attributions
 Overview
Overview Delay system
Delay system Semantic containment
Semantic containment Restriction enzyme system
Restriction enzyme system MAGE
MAGE Suicide system
Suicide system Encapsulation
Encapsulation Synthetic import domain
Synthetic import domain Safety Questions
Safety Questions Safety Assessment
Safety AssessmentContents |
Overview
We want to prevent our genetic construct from conferring an advantage to other organisms. Horizontal gene transfer (HGT) can be performed either by conjugation, transduction, or transformation. As these processes involve two parties, our genetically modified bacteria and some wild type population, and as we will not modify wild type populations, we cannot assume that HGT is fully avoidable. Semantic containment [1] means that our bacteria won't be able to "speak" with other organisms, since they don't speak the same "language", the language being DNA. Our system will read the stop codon TAG as the amino-acid serine. It means that in our bacteria the stop codon will be translated into a serine, whereas in wild type bacteria this protein will be truncated and will not confer an advantage to these cells.

Semantic containment principle. The information carried by the DNA cannot be read by other organism
Objectives
Here we want to show that semantic containment works as expected. First we had to choose between two tRNA amber suppressor, either serine, or tyrosine. For that we calculate the abilities for the amber codon to reverse to a serine or tyrosine or related amino-acid that could conserve the function. Secondly we create a biobrick with a tRNA Amber suppressor ([http://partsregistry.org/Part:BBa_K914000 BBa_K914000]), in order to have a reliable biobrick, with characterization of it. Thirdly, to test the latter biobrick, we built the biobrick [http://partsregistry.org/Part:BBa_K914009 BBa_K914009], that contain an an amber codon instead of one of it serine amino-acid.
With more time we will try to increase the robustness of this system, which is null when the tRNA amber suppressor is transferred too. We will try to create a new library of plasmid backbones in the part registry, where all backbones have at least two amber mutations. The idea is that all the community will be able to improve this library, either by adding new contained backbones, or by adding amber mutations on the same backbone.
Design
Calculation of serine and tyrosine weakness
In order to know which of these two amino-acids is the less robust to mutation from a 'TAG' codon (amber codon), we will calculate a score of weakness. The weakness of an amino-acid is defined here by its abilities to not revert to the same amino-acid or any other similar, from the amber codon. The score is calculated using the following formula :
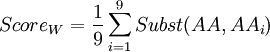
Where i is one of the nine amino-acids accessible after 1 mutation. Subst(AA,AAi) calculate the similarity score, using a BLOSUM62 matrix, between serine or tyrosine (AA) and one of the nine amino-acids around (AAi). The lowest score is the weakest.
Qualitative experiment : does it work?
We are going to transform a plasmid with a the Kan* gene into a MG1655 strain that contain either pSB1C3::supD, or pSB1C3::RFP. We plate them on Chloramphenicol and Kanamycin. The Kan* is supposed to be non functional without an amber suppressor.
Quantitative experiment : Is it working well? Is the amber mutation leaky?

We are going to use the following strains, all in the E. coli strain MG1655. To quantify the leakiness in terms of expression of the Kan* gene, we sill perform real time experiment, where we will measure the growth rate of each of these strains in different concentration of kanamycin. In case of leakiness, the Kan*+RFP strain will be able to grow in higher concentration of kanamycin than the negative control.
We will also be able to quantify the functionality of the Kan*+supD strain, by comparing with the positive control.
Experiments and results
Weakness calculation
We made a Python script that will calculate the score of weakness, with all amino-acids (not only serine or tyrosine), and will sort a list of score, with the BLOSUM62, BLOSUM80, BLOSUM100.
taux de mutation = 1e-09 codon initial : TAG matrice de similarite : blosum62
('A', [-1.5555555563703704e-09])
('C', [-2.444444445851852e-09])
('D', [-1.888888889851852e-09])
('E', [-6.666666674444443e-10])
('F', [-8.888888904814817e-10])
('G', [-2.4444444460740747e-09])
('H', [-7.777777784814815e-10])
('I', [-2.000000001703704e-09])
('K', [-6.666666674444443e-10])
('L', [-1.4444444459629632e-09])
('M', [-1.000000000925926e-09])
('N', [-1.5555555559999998e-09])
('P', [-2.333333335e-09])
('Q', [-2.2222222285185186e-10])
('R', [-1.2222222231111112e-09])
('S', [-1.0000000002222223e-09])
('T', [-1.4444444451481483e-09])
('V', [-1.7777777793333334e-09])
('W', [-2.2222222474074086e-10])
('Y', [4.4444444307407385e-10])
Characterisation of X
Experimental setup
Describe the experiment
Results
Present your results
Testing of the system
Experimental setup
Describe the experiment
Results
Present your results