 "
"
Team:USTC-Software/algorithms and methods
From 2012.igem.org
| (One intermediate revision not shown) | |||
| Line 37: | Line 37: | ||
<p class="h2">2. Selection phase</p> | <p class="h2">2. Selection phase</p> | ||
<p class="main">The fitting function, or score function, is used to evaluate each cell according to the mathematical model in each one. Before this phase begins, the ODE model of each cell should be firstly extracted. From all the ODEs, the software can get the simulated data. The score function here is to give each cell a score by comparing the simulated data and the input data. To make it clear in a mathematical way, the scoring function is:</p> | <p class="main">The fitting function, or score function, is used to evaluate each cell according to the mathematical model in each one. Before this phase begins, the ODE model of each cell should be firstly extracted. From all the ODEs, the software can get the simulated data. The score function here is to give each cell a score by comparing the simulated data and the input data. To make it clear in a mathematical way, the scoring function is:</p> | ||
| - | <p class="list">1)</p> | + | <p class="list">1)<img src="https://static.igem.org/mediawiki/2012/7/7d/USTC-Software-images-Score-Function-1.png" alt="function_1"></p> |
| - | <p class="list">2)</p> | + | <p class="list">2)<img src="https://static.igem.org/mediawiki/2012/7/7c/USTC-Software-images-Score-Function-2.png" alt="function_2"></p> |
<p class="main">represents the input data of the ith species at the jth time point, and the represents the calculated data of the ith species at the jth time point. So these two functions actually calculates the variance of simulated behavior and the input behavior.</p> | <p class="main">represents the input data of the ith species at the jth time point, and the represents the calculated data of the ith species at the jth time point. So these two functions actually calculates the variance of simulated behavior and the input behavior.</p> | ||
<p class="main">Thus after each cell are given a score, Quicksort Algorithm is utilized in ranking all the 2n cells. Then the first n cells will remain for the next generation, the other cells will be eliminated.</p> | <p class="main">Thus after each cell are given a score, Quicksort Algorithm is utilized in ranking all the 2n cells. Then the first n cells will remain for the next generation, the other cells will be eliminated.</p> | ||
| Line 54: | Line 54: | ||
<p class="main">In simple pseudocode, the algorithm can be expressed as this:</p> | <p class="main">In simple pseudocode, the algorithm can be expressed as this:</p> | ||
<pre> | <pre> | ||
| - | + | Function quicksort('arrary') | |
| - | + | If length('array') <=1 | |
| - | + | return 'array' | |
| - | + | select and remove a pivot value 'pivot' from 'array' | |
| - | + | create empty list 'less' and 'great' | |
| - | + | for each 'x' in 'array' | |
| - | + | if 'x' <= 'pivot' then appendix 'x' to 'less' | |
| - | + | else appendix 'x' to 'great' | |
| - | + | return concatenate(quicksort('less'), 'pivot', quicksort('great')) | |
</pre> | </pre> | ||
<p class="main">In our case, the array stands for the scores of all the cells. Here we use Quicksort Algorithm to rank all the cells according to their scores, and then the first several cells will be selected waiting for the next generation.</p> | <p class="main">In our case, the array stands for the scores of all the cells. Here we use Quicksort Algorithm to rank all the cells according to their scores, and then the first several cells will be selected waiting for the next generation.</p> | ||
| Line 70: | Line 70: | ||
<p class="main">This recursive method aims to find small matrix in a big matrix, and recursion makes it universal to every case. Imagine finding an m*m matrix in a n*n matrix (n>m), the finding steps are as follows:</p> | <p class="main">This recursive method aims to find small matrix in a big matrix, and recursion makes it universal to every case. Imagine finding an m*m matrix in a n*n matrix (n>m), the finding steps are as follows:</p> | ||
<pre> | <pre> | ||
| - | + | FindMatrix(n*n database matrix, m*m target matrix) | |
| - | + | If (m ==1 ) | |
| - | + | Return target matrix | |
| - | + | Else findMatrix( n*n database matrix, (m-1)*(m-1) target matrix) | |
| - | + | Return choices | |
</pre> | </pre> | ||
<p class="main">Computational tests have proved that this recursion method is efficient and time saving in finding matrix. And as for our database, two kinds of database matrix of 773*773, 549*549 are generated on users choice.</p> | <p class="main">Computational tests have proved that this recursion method is efficient and time saving in finding matrix. And as for our database, two kinds of database matrix of 773*773, 549*549 are generated on users choice.</p> | ||
Latest revision as of 12:09, 13 November 2012
Algorithms and Methods
In order to make the computational process less time consuming, some advanced algorithms and classical methods are employed in the software. These algorithms and methods include Genetic Algorithm, Quicksort Algorithm and recursive method. To meet need of the common biological researchers, some innovative and original improvements have been proposed by our team to make the computing time much less and the results much more various.
Genetic Algorithm
Genetic Algorithm resembles the natural way of evolution. This algorithm is routinely used to search for optimal solutions of certain problems, belonging to the larger class of Evolutionary Algorithm. Thus, some terminologies are borrowed from natural evolution process such as generation, mutation, selection and inheritance.
A typical Genetic Algorithm should have the following requirements:
a genetic representation of the solution domain
a fitness function to evaluate solution domain
The method in classical Genetic Algorithm is to reduce the whole process into several generations. After each generation, the result will get closer to the optimum one. Every generation contains two phases: growth phase and selection phase. These two phases mimic natural growth process and selection process. At the very beginning of the Genetic Algorithm, a group of cells are initialized randomly with genes, proteins and reactions between them. Each cell represents a mathematical model, and in our case, this model is presented in Ordinary Differential Equations (ODE). These ODEs can be generated by listing all the reactions in each cell using chemical master equations. Then the evolutions begin.
Here is the introduction to classical phases.
1. Growth phase
Assuming there are n cells in the initialization step, then in growth phase all these cells will duplicate themselves. The duplicated cells will go through randomly mutation process. In our software, these mutations include:
1) Changing the degradation rate of a randomly chosen protein.
2) Changing the kinetic constant of a randomly chosen reaction.
3) Adding a new gene, in the meantime the corresponding protein should be added as well, including the transcriptional reaction and the degradation reaction of the protein.
4) Adding a regulation. Namely adding a regulatory reaction between a gene and a protein, and the kinetic constants are randomly drawn in (0,1).
5) Adding a post transcriptional reaction. As for this case, there are several kinds of modifications
5.1) A+B->AB: Binding between two proteins
5.2) A+B->A: catalytic reaction
5.3) A+BC->B: partial catalytic
5.4) A->A*: post transcriptional modification
5.5) BC->B: partial degradation
After a generation, the 2*n cells will go to another phase.
2. Selection phase
The fitting function, or score function, is used to evaluate each cell according to the mathematical model in each one. Before this phase begins, the ODE model of each cell should be firstly extracted. From all the ODEs, the software can get the simulated data. The score function here is to give each cell a score by comparing the simulated data and the input data. To make it clear in a mathematical way, the scoring function is:
1)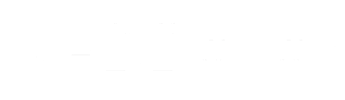
2)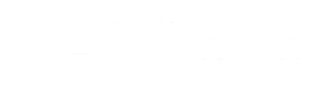
represents the input data of the ith species at the jth time point, and the represents the calculated data of the ith species at the jth time point. So these two functions actually calculates the variance of simulated behavior and the input behavior.
Thus after each cell are given a score, Quicksort Algorithm is utilized in ranking all the 2n cells. Then the first n cells will remain for the next generation, the other cells will be eliminated.
That is a generation of the whole Genetic Algorithm. Then the group of cells will go through several hundred or thousands of generations. The final several cells are assumed to the cells with the best behaviors.
Our Improvements
By merely using classical Genetic Algorithm is proved to be slow in computational process. As for some steps in the algorithm, some cells with potentials may be eliminated due to the low score at that generation. Moreover, the original algorithm does not consider cells with different topology levels and does not sort the cells by complexity, either. Thus, to avoid these problems, we make some important changes to the algorithm, and the results prove to be better and more practical than the classical one.
1. We classify mutations into two kinds: mutation of topology and mutation of parameter. Topology mutation only contains mutation type 3-----adding a new gene. In order to preserve the potential properties of each cell, for some generations in the grown phase cells can only have topology mutations, and then the cells will undergo parameter mutations. This special design of Genetic Algorithm helps preserve cells with potentials. In addition, we can thus provide cells with different complexity levels.
2. To avoid the results concentrated around the local optimum, we initialize several groups of cells with different initial conditions, and we duplicate and selection cells in each group. With this improvement, we will get cells with different behaviors, providing users with more choices.
Quicksort Algorithm
Quicksort Algorithm has been ranked among top 10 algorithms by IEEE. Quicksort method is mainly used in the case of sorting or retrieving. Its properties like time and computational space saving makes it outstanding among all the sort methods, and that is why it is so commonly used in simulations of nearly all the fields.
The core of Quicksort Algorithm is a recursive method which reduces the complexity of the problem step by step, and the final step should be a simple case easy to deal with. Recursion makes the problem less difficult to understand and more feasible in programming.
In simple pseudocode, the algorithm can be expressed as this:
Function quicksort('arrary')
If length('array') <=1
return 'array'
select and remove a pivot value 'pivot' from 'array'
create empty list 'less' and 'great'
for each 'x' in 'array'
if 'x' <= 'pivot' then appendix 'x' to 'less'
else appendix 'x' to 'great'
return concatenate(quicksort('less'), 'pivot', quicksort('great'))
In our case, the array stands for the scores of all the cells. Here we use Quicksort Algorithm to rank all the cells according to their scores, and then the first several cells will be selected waiting for the next generation.
Recursion method
As we integrate all the regulation in a matrix, and to make the database compatible with the software, we use a recursion method to find the regulatory matrix in the database matrix. After finding the matrix, we then can used the parts in the database to rebuild the system.
This recursive method aims to find small matrix in a big matrix, and recursion makes it universal to every case. Imagine finding an m*m matrix in a n*n matrix (n>m), the finding steps are as follows:
FindMatrix(n*n database matrix, m*m target matrix)
If (m ==1 )
Return target matrix
Else findMatrix( n*n database matrix, (m-1)*(m-1) target matrix)
Return choices
Computational tests have proved that this recursion method is efficient and time saving in finding matrix. And as for our database, two kinds of database matrix of 773*773, 549*549 are generated on users choice.